テクノロジー
2024年11月15日scikit-learnとは

scikit-learnは、Pythonで機械学習を行うためのライブラリです。
scikit-learnを使用することで、データマイニング(統計学や人工知能などの分析手法を駆使して、データからパターンを見出すための分析手法)やデータ解析といった処理を簡単に実行できます。
目次
著者プロフィール
ゴール
scikit-learnとは
欠損値への対応
欠損値の除外
欠損値の補完
カテゴリ変数の数値化
ラベルエンコーディング
One-hotエンコーディング
特徴量の正規化
分散正規化
最小最大正規化
まとめ
著者プロフィール
IT分野における教育の先駆者として、多くのエンジニアを育成するプログラミングスクールの運営、Web開発やAI研修を行なっています。幅広いレベルの受講生に対して実践的なスキルを提供。生徒の成長を第一に考え、効果的で魅力的な教育プログラムの設計に情熱を注いでいます。
ゴール
- scikit-learnの役割について理解する
- scikit-learnを使った基本的な前処理ができるようなる
scikit-learnとは
scikit-learnは、Pythonで機械学習を行うためのライブラリです。
scikit-learnを使用することで、データマイニング(統計学や人工知能などの分析手法を駆使して、データからパターンを見出すための分析手法)やデータ解析といった処理を簡単に実行できます。
機械学習を使ったデータ分析を行うには、使用するデータを機械側で分析可能な状態にしておく必要があります。
このデータを機械側で分析可能な状態にする工程のことを前処理と言います。
機械学習を行う上で、前処理はとても重要なプロセスであり、この作業を疎かにした場合、誤った分析結果が出力されたり分析自体が実行できないといった問題が発生します。
ここでは、代表的な前処理である以下のテーマについて説明します。
- 欠損値への対応
- カテゴリ変数の数値化
- 特徴量の正規化
欠損値への対応
欠損値は、データの誤入力や通信上の不具合などによって誤った値が登録された場合に発生します。
欠損値が入ったままのデータではデータ解析が適切に行われないため、前処理の工程で適切に対処しておく必要があります。
欠損値への対応における代表的な手法として、欠損値の除外と欠損値の補完とがあります。
ここでは、欠損値を含む以下のデータセットを使って、それぞれの手法について説明します。
以下のコードを実行し、中身を確認しておきましょう。
import numpy as np
import pandas as pd
df = pd.DataFrame(
{
'A': [1, 2, 3, 4, np.nan],
'B': [10, np.nan, 30, 40, 50],
'C': [np.nan, 200, 300, 400, 500]
}
)
df
[実行結果]
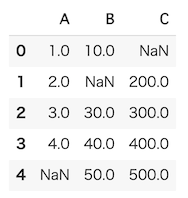
NumPyのテキストで説明したように、np.nanを使用することで、明示的に欠損値をデータに含めることができます。
欠損値の除外
DataFrameに欠損値が含まれているかどうかはisnullメソッドで確認できます。
df.isnull()
[実行結果]

このように、各要素に対して判定を行い、欠損値である場合はTrue、そうでない場合はFalseが返されます。
欠損値を除外するには、Pandasのテキストでも説明したようにdropnaメソッドを使用します。
df.dropna()
[実行結果]
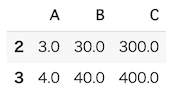
このように、欠損値が含まれる行をまるごと削除できます。
欠損値の補完
先程説明した欠損値を除外する処理には、データ数自体が減ってしまうという欠点があります。
特に手元にあるデータの数が少ない状態で欠損値を除外した場合、さらにデータ数が減ってしまいます。
このような問題を解消する方法として、欠損値を補完する手法があります。
Pandasのテキストでfillnaメソッドを使って欠損値を補完する方法について説明しましたが、ここでは、scikit-learnのimputeモジュールのSimpleImputerクラスを使用する方法について説明します。
SimpleImputerクラスは、以下のようにインポートします。
from sklearn.impute import SimpleImputer
次に、欠損値を補完するSimpleImputerクラスのインスタンスを作成します。
この際、引数のstrategyパラメータに補完する値を指定します。
ここでは、平均値で補完するためmeanを指定します。
imp = SimpleImputer(strategy='mean')
次に、fitメソッドを使ってDataFrameの統計量を計算します。
今回は平均値の計算が行われ、SimpleImputerインスタンスに計算結果が保管されます。
imp.fit(df)
[実行結果]
SimpleImputer()
最後にtransformメソッドを使って、欠損値を平均値で補完する処理を実行します。
imp.transform(df)
[実行結果]
array([[ 1. , 10. , 350. ],
[ 2. , 32.5, 200. ],
[ 3. , 30. , 300. ],
[ 4. , 40. , 400. ],
[ 2.5, 50. , 500. ]])
実行結果からそれぞれの値が平均値で補完されているのが確認できます。
また、結果はDataFrameではなく、ndarrayが返されます。
補完する値を指定するstrategyパラメータには、他にもmedian(中央値)、most_frequent(最頻値)なども指定できます。
scikit-learnで欠損値を補完する際に実行したコードをまとめると、以下のようになります。
from sklearn.impute import SimpleImputer
imp = SimpleImputer(strategy='mean')
imp.fit(df)
imp.transform(df)
カテゴリ変数の数値化
カテゴリ変数とは、データがどのカテゴリに属するかを表した変数を指します。
例えば、以下のような男女の年齢と性別を記録したデータがあるとします。
df = pd.DataFrame([[23, 'male'],
[43, 'female'],
[31, 'male'],
[35, 'female'],
[40, 'male']],
columns=['age', 'sex'])
df
[実行結果]

このデータのうち、sexカラムの値はmaleとfemaleで分類できることからカテゴリ変数に該当します。
分析の中でカテゴリ変数を扱う場合、機械側が処理しやすいように数値に変換しておく必要があります。
カテゴリ変数を数値に変換する代表的な手法として、ラベルエンコーディングとOne-hotエンコーディングがあります。
それぞれの手法について、以下で説明します。
ラベルエンコーディング
ラベルエンコーディングとは、maleを数値の0、femaleを数値の1のようにカテゴリごとに数値を割り振る手法です。
scikit-learnには、ラベルエンコーディングを実行するフレームワークが用意されています。
ここでは、preprocessingモジュールのLabelEncoderクラスを使用する方法について説明します。
まず、以下のようにインポート文を記述し、LabelEncoderクラスをインポートします。
from sklearn.preprocessing import LabelEncoder
次に、LabelEncoderクラスのインスタンスを作成します。
le = LabelEncoder()
次に、fitメソッドを使って指定したデータに対してエンコーディングを実行し、実行結果をLabelEncoderクラスに保管します。
ここでは、sexカラムの値をエンコーディングします。
le.fit(df['sex'])
[実行結果]
LabelEncoder()
最後にtransformメソッドを使って、sexカラムの値にエンコーディングした結果を適用します。
le.transform(df['sex'])
[実行結果]
array([0, 1, 0, 1, 0])
sexカラムの値が数値でエンコーディングされているのが確認できます。
LabelEncoderクラスのclasses_属性を使えば、どの値がエンコーディングされたかを確認できます。
le.classes_
[実行結果]
array(['male', 'female'], dtype=object)
上記の結果から、maleとfemaleの値がエンコーディングされたのが確認できます。
ラベルエンコーディングで実行したコードをまとめると、以下のようになります。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['sex'])
le.transform(df['sex'])
One-hotエンコーディング
One-hotエンコーディング(ダミー変数化)とは、カテゴリ変数(ダミー変数)の種類と同じ数だけ列を用意し、それぞれの列に0と1を入力してどのカテゴリに該当するかを表現します。
以下は、社員のポストをOne-hotエンコーディングを使って表した例です。

カテゴリに該当する場合は1、該当しない場合は0を入力します。
以下の男女の年齢と性別のデータを使って、実際にOne-hotエンコーディングを実行してみましょう。
df = pd.DataFrame([[23, 'male'],
[43, 'female'],
[31, 'male'],
[35, 'female'],
[40, 'male']],
columns=['age', 'sex'])
df
[実行結果]
One-hotエンコーディングは、Pandasのget_dummy関数を使用するのが一般的ですが、ここではscikit-learnを使用する方法について説明します。
One-hotエンコーディングの処理を実行するために、scikit-learnからpreprocessingモジュールのOneHotEncoderクラスとcomposeモジュールのColumnTransformerクラスをインポートします。
OneHotEncoderクラスとColumnTransformerクラスは、それぞれ以下のようにインポートします。
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
ColumnTransformerクラスを使用することで、DataFrameに対して列ごとに異なった処理を実行できます。
まず、ColumnTransformerクラスのインスタンスを作成します。
ohe = ColumnTransformer([("OneHotEncoder", OneHotEncoder(), [1])], remainder = 'passthrough')
ColumnTransformerクラスをインスタンス化する際にいくつか引数を渡しています。
第一引数には、タプルのリストの中で3つのパラメータを指定します。
- name:名前(任意の値を指定します。)
- transformer:使用する推定器
- エンコーディング対象(カラムの場合、カラム番号とカラム名のどちらでも指定できます。)
第二引数のremainderパラメータでは、変換処理を行なった列のみをインスタンスに含めるか、あるいはすべての列をインスタンスに含めるかを指定しています。
passthroughを指定した場合、すべての列を含むインスタンスが生成されます。
次に、DataFrameに対してOne-hotエンコーディングを実行します。
ここでは、copyメソッドを使ってDataFrameのコピーを作成し、そのコピーに対してOne-hotエンコーディングを適用します。
df_ohe = df.copy()
ohe.fit_transform(df_ohe)
[実行結果]
array([[ 1., 0., 23.],
[ 0., 1., 43.],
[ 1., 0., 31.],
[ 0., 1., 35.],
[ 1., 0., 40.]])
元々ageとsexの2列の構成でしたが、One-hotエンコーディングを実行したことで3列分のデータからなるndarrayが返されます。
ageカラムのデータに加え、sexカラムの値が0と1の数値で表現されているのが確認できます。
先ほどColumnTransformerクラスをインスタンス化する際に指定したremainderパラメータを記載しなかった場合は、以下のようにエンコーディングされたageカラムのデータのみが返されます。
array([[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.]])
特徴量の正規化
特徴量の正規化とは、特徴量の大きさを揃える処理のことです。
特徴量の桁数が大きく異なるもの同士を使って分析を行なった場合、特徴量の大きな値が分析結果に大きく影響を与えてしてしまい、逆に特徴量の小さなデータが分析結果に反映されなくなってしまいます。
このような特徴量の偏りを無くし、同じ基準でデータを評価できるようにしたい場合、前処理の工程で特徴量を正規化します。
特徴量の正規化の代表的な手法として、分散正規化と最小最大正規化とがあります。
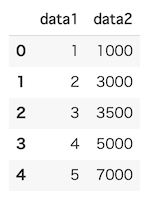
ここでは、以下のデータセットを使って、それぞれの手法について説明します。
以下のコードを実行し、中身を確認しておきましょう。
import pandas as pd
df = pd.DataFrame({
'data1': [1, 2, 3, 4, 5],
'data2': [1000, 3000, 3500, 5000, 7000]
})
df
[実行結果]
分散正規化
分散正規化は、特徴量の平均値が0、標準偏差が1になるよう特徴量を変換する手法です。
分散正規化には、scikit-learnのpreprocessingモジュールのStandardScalerクラスを使用します。
StandardScalerクラスは、以下のようにインポートします。
from sklearn.preprocessing import StandardScaler
初めに、StandardScalerクラスのインスタンスを作成します。
scaler = StandardScaler()
次に、fit_transformメソッドを使ってデータを正規化します。
scaler.fit_transform(df)
[実行結果]
array([[-1.41421356, -1.44280393],
[-0.70710678, -0.44776674],
[ 0. , -0.19900744],
[ 0.70710678, 0.54727045],
[ 1.41421356, 1.54230764]])
正規化によって同じような水準で比較できる値に変換されているのが確認できます。
最小最大正規化
最小最大正規化は、特徴量の最大値が1、最小値が0になるように特徴量を変換する手法です。
最小最大正規化には、scikit-learnのpreprocessingモジュールのMinMaxScalerクラスを使用します。
MinMaxScalerクラスは、以下のようにインポートします。
from sklearn.preprocessing import MinMaxScaler
初めに、MinMaxScalerクラスのインスタンスを作成します。
scaler = MinMaxScaler()
次に、fit_transformメソッドを使ってデータを正規化します。
scaler.fit_transform(df)
[実行結果]
array([[0. , 0. ],
[0.25 , 0.33333333],
[0.5 , 0.41666667],
[0.75 , 0.66666667],
[1. , 1. ]])
正規化によって同じような水準で比較できる値に変換されているのが確認できます。
まとめ
- 欠損値を補完することで、データ数を減らすことなく欠損値を除外できる。
- カテゴリ変数を数値化する手法には、ラベルエンコーディングやOne-hotエンコーディングなどがある。
- 分散正規化では、特徴量を平均値0、標準偏差1とする正規化が行われる。
- 最小最大正規化では、特徴量を最大値1、最小値0とする正規化が行われる。




